Cross Validation in Machine Learning
Statistics & Machine learning
Cross validation
Cross validation becomes an increasingly popular method in either theoretical or practical research. There are usually two types of cross validation techniques. 1) The first is to provide a statistical analysis about how accurately a predictive model will perform in practice. 2) The second is to find the optimal hyperparameter or tune hyperparameter. They usually refer to model evaluation and model selection, respectively.
I think it is important to clarify the difference between these two types of cross validation techniques. That always confuses beginners, as it confused me when I was learning this technique. I would say the Wikipedia article is not good enough for beginners. Wikipedia refers the second one as nested cross-validation, but it is obviously not clear.
In effect, the basic idea of them is the same: out-of-sample testing. Next, I will describe these two cross validation method:
Model evaluation
In the real world, we usually have a dataset (\(S=\{1,...,n\}\)) including X and y. We can split the dataset as training set and test set. For a prediction task, a model is training on the training data (X_train, y_train), then the trained model is tested on the test data (X_test, y_test). Selecting a training set once randomly could cause selection bias or overfitting, and it does not reflect the real performance of a model on an independent dataset (i.e., an unknown dataset, for instance from a real problem).
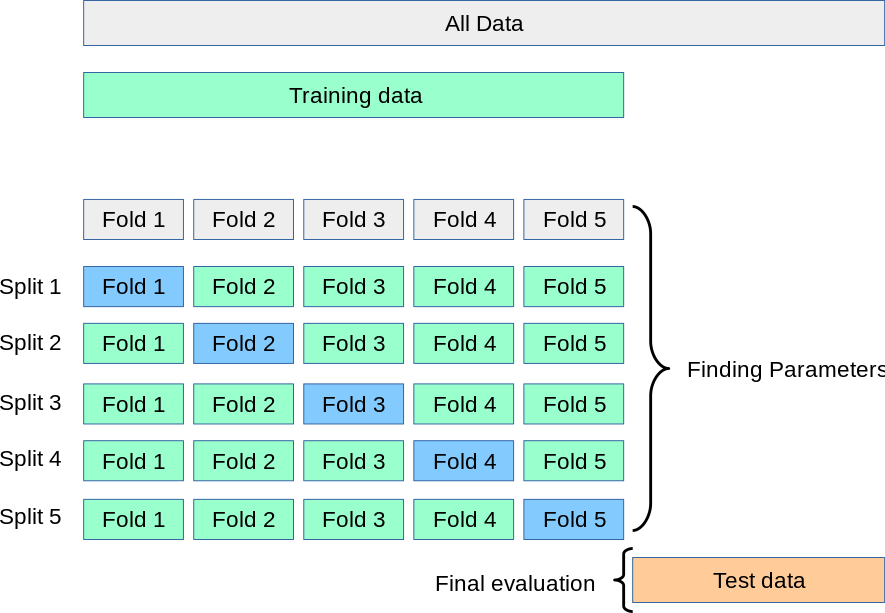
To solve this problem, we can calculate the average performance of model on iterative datasets. In the figure, I illustrate the 5-fold cross validation for model evaluation. Note that validation fold is test data.

Model selection
This technique provides a objective way to decide the tuning parameter (hyperparameter in machine learning). Note that, in the model selection, we just split the training set to K folds, while we split the whole dateset in model evaluation (see the figure). When \(K = n\), we call this leave-one-out cross-validation, because we leave out one data point at a time.
K-fold cross validation considers training on all folds of data except kth fold, and then test the model on kth fold of data. Then, we repeat this process on other splits, iterating over \(k=1,...,K\). For \(k=1,...,K\), we calculate the total error (calculate the performance, i.e. MSE showing down below) on the test fold:
\[e_k(\theta) = \sum_{i\in S^k} (y_i^k - \hat{f}_{\theta}^{-k}(x_i^k))^2\]where \((x_i^k, y_i^k)\) is the data in test fold (\(S^k\)). \(\hat{f}_{\theta}^{-k}\) is the estimated model from \(K-1\) training folds (\(S^{-k}\)) for hyperparameter \(\theta\). Then, we compute the average error over all folds for each hyperparameter \(\theta\):
\[CV(\theta) = \frac{1}{n}\sum_{k=1}^K e_k(\theta) = \frac{1}{n}\sum_{k=1}^K\sum_{i\in S^k} (y_i^k - \hat{f}_{\theta}^{-k}(x_i^k))^2\]Finally we can find the optimal hyperparameter \(\hat{\theta}\) where the model has the best performance:
\[\hat{\theta}= \underset{\theta\in \{\theta_1,...,\theta_m\}}{\operatorname{argmin}} CV(\theta)\]I recommend you read the paper A Bias Correction for the Minimum Error Rate in Cross-validationData miningAdvanced Methods for Data Analysis
In my github repository PyCV, I have written some python codes for the two types of cross validation. However, those codes are just demos which maybe do not fit the problems you meet. If you need more general python or julia codes, please feel free to contact me. I will see if it is necessary to update the repository.